When working with Large Language Models, a recurring challenge emerges: every character in a structured data payload costs tokens, and tokens incur costs. While JSON has long been the universal standard for data exchange, the age of AI agents and LLM-driven applications calls for a re-evaluation of data serialization methods.
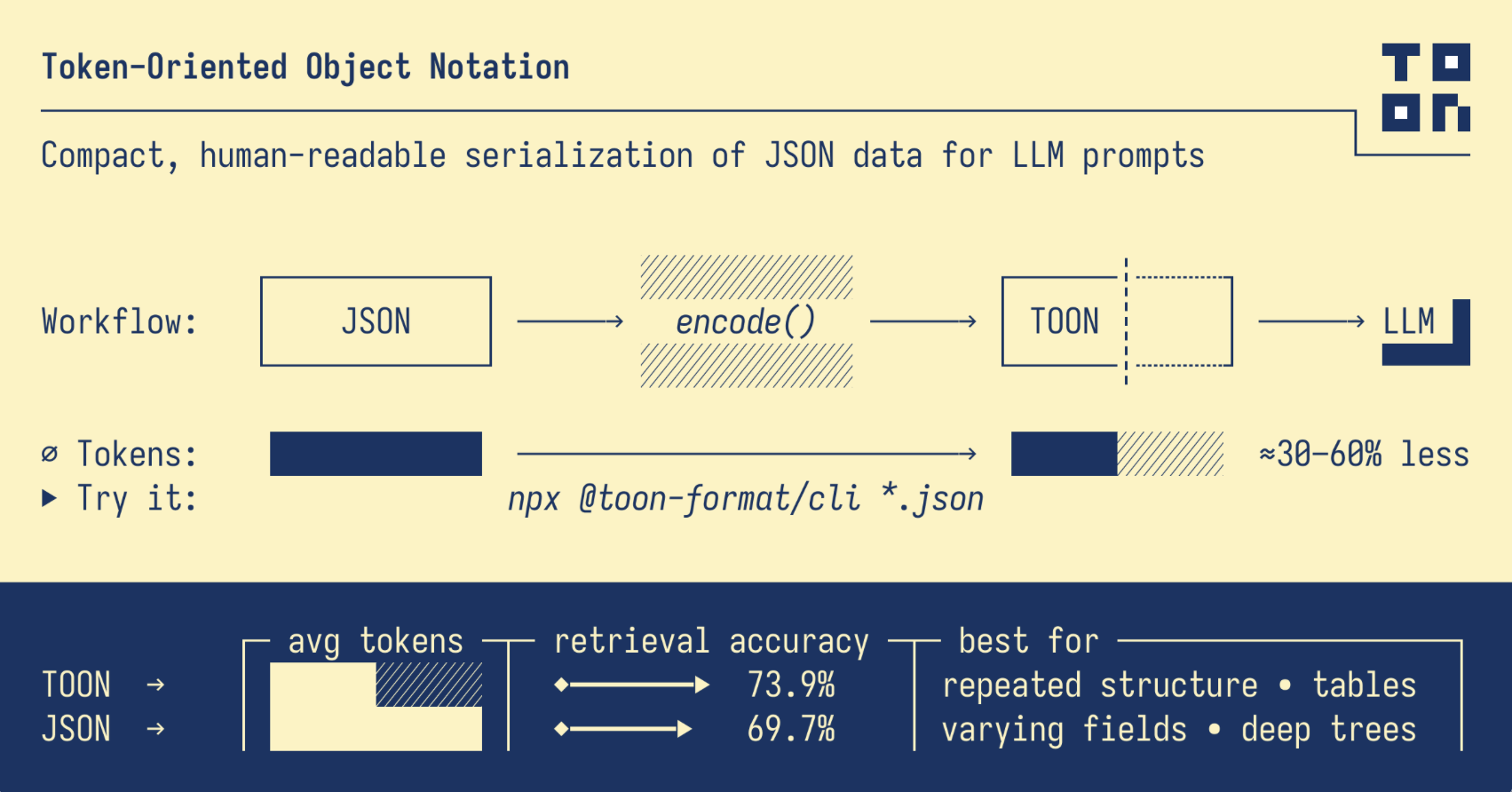
Token-Oriented Object Notation (TOON) is a new data format designed specifically for this challenge. It can achieve a token reduction of 30-60% compared to JSON while maintaining human readability and supporting identical data structures (e.g. TOON GitHub).
Why Token Efficiency Matters
In traditional API development, minor variations in data size are often negligible. However, when feeding structured data to LLMs, every bracket, comma, and quotation mark is processed as a billable token. For high-volume AI applications—such as agentic workflows, RAG systems, or data analysis pipelines—this overhead accumulates quickly, impacting both cost and latency.
Consider a benchmark scenario involving a dataset of 100 GitHub repository records. In standard JSON, this dataset consumes 15,145 tokens. The same data in TOON format uses just 8,745 tokens—a 42.3% reduction. For operations processing thousands of such requests daily, the savings become significant.
Understanding TOON’s Design
TOON integrates effective elements from established formats, combining YAML’s indentation-based structure with CSV’s tabular data representation. Instead of enclosing every object in curly braces and repeating field names for each record, TOON declares the schema once, presenting data in a compact, spreadsheet-like layout.
A practical comparison highlights the difference. A user list in traditional JSON appears as follows:
{
"users": [
{"id": 1, "name": "Alex", "role": "admin", "email": "alex@example.com"},
{"id": 2, "name": "Maria", "role": "user", "email": "maria@example.com"},
{"id": 3, "name": "Tom", "role": "user", "email": "tom@example.com"}
]
}The equivalent data in TOON is much more concise:
users[^3]{id,name,role,email}:
1,Alex,admin,alex@example.com
2,Maria,user,maria@example.com
3,Tom,user,tom@example.comThe efficiency gains are clear—the format eliminates repetitive braces, brackets, and field names.
Performance Beyond Token Count
A particularly noteworthy finding from TOON benchmarks is the improvement in model accuracy. In tests involving 209 data retrieval questions across multiple LLMs, TOON achieved 73.9% accuracy compared to JSON’s 69.7%, all while using 39.6% fewer tokens.
This suggests benefits beyond simple data compression. TOON’s tabular structure appears to enhance how LLMs parse and reason about structured data, especially for aggregation, filtering, and other structure-aware operations. The format’s clarity helps models extract information more reliably, which can directly translate to better agent performance.
Practical Implementation
TOON is supported by libraries in major programming languages, including Python (toon-py), JavaScript/TypeScript, and Elixir. The format offers lossless serialization for the same data model as JSON—including objects, arrays, and primitives—making migration paths straightforward.
For data and AI engineers, TOON is particularly advantageous in specific use cases:
- When TOON makes sense: It is ideal for structured agent inputs (e.g., user lists, product catalogs), flat or tabular data, and high-volume workflows where token costs are a concern.
- When JSON remains appropriate: JSON is still the better choice for deeply nested hierarchical data, standard REST API integrations requiring JSON compliance, and datasets with mixed or varying structures across records.
Strategic Considerations
From a strategic viewpoint, TOON represents a move toward AI-native data formats. Much like JSON emerged to serve web APIs more efficiently than XML, TOON addresses the specific constraints of LLM-based systems. This is highly relevant for organizations developing AI agents, implementing autonomous workflows, or managing large-scale prompt engineering operations.
A pragmatic approach is recommended: TOON should not replace JSON universally. Instead, it can serve as a translation layer within an AI pipeline. By maintaining JSON for external APIs and system integrations while converting to TOON for LLM interactions, developers can achieve both compatibility and optimization.
Looking Forward
As AI systems grow in sophistication and autonomy, token efficiency will increasingly influence architectural decisions. While TOON may not become a new universal standard, it effectively solves a pressing problem for professionals working at the intersection of data engineering and AI.
For teams managing token-intensive AI operations, TOON provides a practical solution for reducing costs and enhancing model performance. The format is production-ready, well-documented, and actively maintained, making it a valuable tool to consider for modern AI infrastructure. The adoption of token-optimized formats like TOON will be key to building more efficient and cost-effective AI systems.
Comments are closed.